Python实用手册03 词云
接下来,让我们一起来完成一项具有一定实际价值的工作吧!
在数据可视化领域,我们经常会使用词云来对文字中词语频率进行统计。网络当中也有许多类似Wordle 、图悦图云生成网站。不过佛家有一句禅语:
莫向外求,但从心觅
我们可以片面的将这句话用在编程当中——双手敲过的代码才属于自己。 接下来就让我们通过 Python 自己编写一个词云生成器吧!
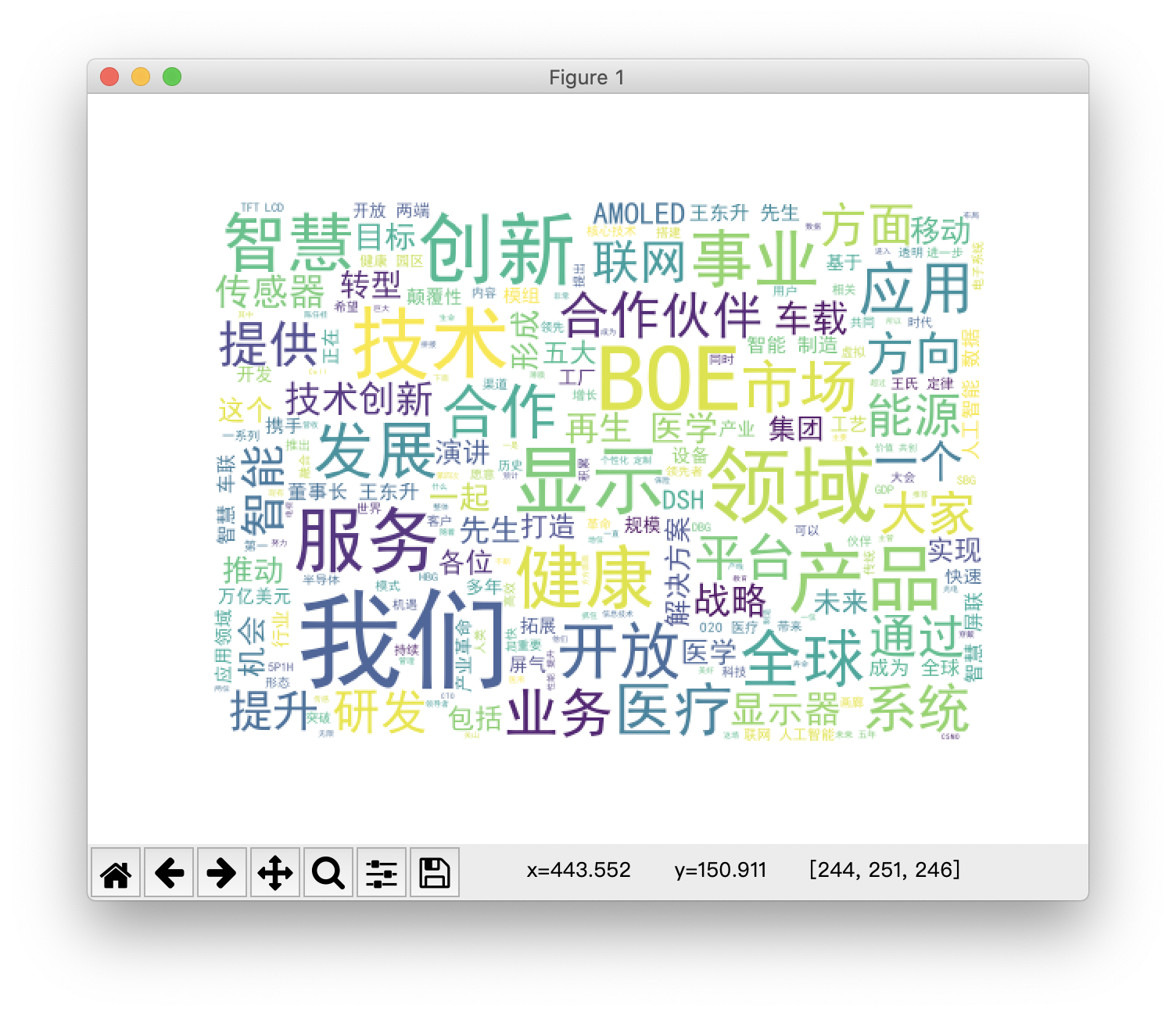
首先是效果图,我节选了 BOE(目前国内最大的面板生产企业)现任董事长在 2018 年全球创新合作伙伴峰会中的演讲,让词云通过分析这篇演讲稿来看看这位企业家为合作伙伴勾勒出的物联网蓝图是怎样的:
服务、技术、创新这些词语在演讲中被大量提及,通过这样一张图片,就能对这篇演讲的大概内容有一定的了解。那么 Python 是如何生成这样一副文字大小颜色方向各异的复杂图片呢? 其实十分简单,仍旧是老规矩,NoBB,Show Code!
# 词云图
import matplotlib.pyplot as plt
import jieba
from wordcloud import WordCloud
from os import path
localpath = path.dirname(__file__) # 获取当前工作路径
# 获取文件,注意这里要看编码格式
text = open(localpath+r'/words.txt', 'r', encoding='UTF-8').read()
# 剪切单词
text_cut = jieba.cut(text)
# 单词拼接
result = ' '.join(text_cut)
# 生成次云图
wc = WordCloud(
# 字体路径
font_path=localpath + r'/simhei.ttf',
# 背景颜色
background_color='white',
# 图片宽度
width=500,
height=350,
# 字体的大小
max_font_size=70,
min_font_size=5,
)
# 生成词云图片
wc.generate(result)
plt.imshow(wc)
plt.axis('off')
plt.show()你一定很惊讶短短 20 多行代码就实现了词云这样复杂的功能。这都归功于 Python 丰富的各类库 请允许我再次唠叨一下库的定义。
- 所谓库就是 Python 提供的实现一类功能的具有目录层次结构的程序集合。
简而言之,库就是 Python 提供给我们的,帮我们实现功能的工具包,每个工具包都能实现一个或者一类功能。本次程序我们用到了四个库:
- matplotlib:Matplotlib 是一个 Python 2D 绘图库,它能够快速辅助数据分析人员生成图表、直方图、功率谱、条形图、误差图、散点图。pyplot 是 Matplotlib 的一个命令风格函数的集合,使 matplotlib 的机制更像 MATLAB,matplotlib 的 pyplot 子库提供了和 matlab 类似的绘图 API,方便用户快速绘制 2D 图表。
- jieba:jieba 是一种中文分词组建,他通过一定计算逻辑可以将一句完整的中文句子拆解成一个个词语。
- wordcloud 是 Python 用于构建词云的工具包,其功能强大,支持自定义词云各项参数。
- path:这是 Python 标准库(自带的、无需安装的)中提供的用于文件访问、处理的库
通过调用这些库的 API,我们就能够很容易的实现词云这样复杂的图片。 你肯定已经早早将程序敲到电脑中编译运行了,但是却出现了这样的错误:
发生异常: ModuleNotFoundError
No module named 'matplotlib'为什么呢?因为我们的程序中使用到了 matplotlib、jieba、wordcloud 这些外部库,外部库需要我们下载安装到自己电脑上才可以运行。坏消息是我们要下载三个库才能保证程序正常跑起来,好消息安装三个库非常容易!
之前我们提到了包管理器,python 内置了包管理器,使用包管理安装外部库的命令格式如下:
pip3 install SomePackage注意这里是 pip3(在 python 进入 3.X 时代包管理应当使用 pip3 这个命令)
接下来让我们开始安装所需的三个外部包。打开命令行程序(windows 系统 开始 ➡️ 运行 ➡️cmd,MacOS 系统使用终端)
pip3 install matplotlib #安装matplotlib
pip3 install jieba #安装jieba
pip3 install wordcloud #安装wordcloud不出意外的情况下这些包就都安装好了,如果安装过程中有疑问,最好百度/Google/dogedoge 一下,善用搜索引擎。 万事俱备只欠东风,接下来我们逐行对程序进行分析。
import matplotlib.pyplot as plt- 这句话翻译成汉语很简单:引用 matplotlib 库的 pyplot 功能包,并将其命名为’plt’
- matplotlib.pyplot 也可以写为 from matplotlib import pyplot 这样的形式,这种形式我们在后面也会遇到,只需知道他的意思就是从 matplotlib 库中调用 pyplot 功能即可
- 为什么要将其 as plt 呢? 很明显,就是因为 matplotlib.pyplot 太长了,后面我们要多次用到这个命令,索性给他起个名字,方便后续书写。这个名字可以随便命名(尽量符合驼峰命名规则)
import jieba
from wordcloud import WordCloud
from os import path很简单,就是引入其他几个所需的库。(这里三个包都没有使用别名,因为本身长度就不长)
localpath = path.dirname(__file__) # 获取当前工作路径python 是一种若类型语言,所以我们定义变量“localpath”的时候并没有像其他编程语言一样 使用 string 类型符 这句代码的意思是:定义一个变量“localpath”,给这个变量赋值为 当前工作路径。 如何获取当前工作路径呢?使用的方法就是 path.dirname(file),这是 Python os 库中自带的方法,是不是非常方便?
# 获取文件,注意这里要看编码格式
text = open(localpath+r'/words.txt', 'r', encoding='UTF-8').read()这句话定义了一个变量 text,将工作目录下的 words.txt 中的文字赋值给它。 这里用到了一个 python 的 open()函数,open() 函数用于打开一个文件,创建一个 file 对象,相关的方法才可以调用它进行读写。 open()函数代码格式如下:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式:只读,写入,追加等。我们采用了 r 模式,即默认文件访问模式。
- buffering: 可选,设置缓冲,-1 为采用系统默认缓存大小,0 表示不使用,1 表示使用,大于 1 的数字表示缓存区大小
- encoding: 一般使用 utf8(可以正常读取中文)
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的 file 参数类型
这个时候你可能有些疑惑 🤔,道理都懂,但是为什么 open()这个函数在这里要这样写?因为该教程的前半部分主要面向初学者,我们也没有经历过系统性的基础学习,这里对 编程语言中方法(函数)的调用进行说明。
比如本例中 open(localpath+r’/words.txt’, ‘r’, encoding=‘UTF-8’) 这个语句
- open()表示方法名,告知计算机我调用的是什么方法(函数)
- open 中所有内容,我们称之为参数,不同参数用”,“分开。也就是说在本例中,我们调用 open()方法,这个方法使用了三个参数
- 第一个参数告知计算机文件的路径,localpath+r’/words.txt’ 即工作目录下的 words.txt 文件
- 第二个参数告知计算机我们采用 r 的模式读取文件(只读)
- 第三个参数告诉计算机我们用的编码模式
- 给方法定义参数的这个动作我们称之为 传参
希望这样的解释能让你对编程工作中最基础最重要的 方法和参数有基本的理解。
# 剪切单词
text_cut = jieba.cut(text)这一句,我们调用了 jieba 的 cut 方法,将刚刚获取的文件内容 text 传如 cut 方法,这样 jieba 就将我们的 text 自动分词,分为一个一个单词组成的词组。最后将词组赋值给新定义的变量 text_cut
# 单词拼接
result = ' '.join(text_cut)这里有调用了一个 join 方法,传入我们的数组 text_cut。什么意思呢?就是将这分好的一个个词语组合起来,使用空格隔开,组合成一个字符串。 到这里,我们对于文章的处理就结束了,我们将原来的文章分成一个个词语,每个词语用空格隔开。为什么要这样处理呢?没有别的原因,就是因为我们后续调用的 wordcloud 库就是这样规定的,他只能识别这样形式的数据。
# 生成次云图
wc = WordCloud(
# 字体路径
font_path=localpath + r'/simhei.ttf',
# 背景颜色
background_color='white',
# 图片宽度
width=500,
height=350,
# 字体的大小
max_font_size=70,
min_font_size=5,
)
# 生成词云图片
wc.generate(result)这里看似复杂,其实更加简单,我们调用了 wordcould 的方法,并在方法中传入若干参数,通过这些参数定义我们生成词云的样式。 这里尤其需要注意 font_path=localpath + r’/simhei.ttf’ 这一句必不可少,因为 wordcloud 必须知道自己使用的字体文件是什么样的才能正确生成词云。所以我们在工作目录中放入了一个 simhei.ttf 字体文件,方便 wordcloud 调用。
这样我们的一个词云生成器 wc 就定义好了,后续再调用 generate()方法并将处理好的数据变量 result 扔进去即可。
plt.imshow(wc)
plt.axis('off')
plt.show()词云做好了,如何让它显示出来?
- 调用 plt(就是开头引用的 2D 图像生成包)中 imshow()方法将 wc 图片进行显示,
- 调用 plt.axis(‘off’)让它不要生成坐标轴
- 调用 plt.show()方法使其显示出来。
这样我们点击运行后一张词云图就显示出来了,注意工作目录中用到的 word.txt 文件,simhei.ttf 放在github中,你可以自行下载。如果不会使用 github 下载也没关系,自己在网上任意下一个 ttf 的字体文件,自己随便写一个 word.txt 文本文档放到我们写的 python 程序目录中即可。
虽然我说的琐碎,但是在实际编写过程中相信你还是遇到许多问题,失败多次,各种环节出现奇葩的我没有提到的问题。 没关系,多查多想多问。遇到问题,请在下方留言区留言


